My Favorite (Excel) Things | extra.twincities.com
A short readable guide to one of the most vital and fundamental data journalism tools.
As Philip Meyer said in his book, Precision Journalism:
There are two kinds of databases: those that you create yourself and those that were created by somebody else, usually without your convenience in mind.
If you want to be one of those independent collectors of data – because you're paying attention to something that the government or society just isn't – then get used to using spreadsheets. Your ability to be smart at organizing information is going to be just as important as passion (if not much more important) when it comes to accomplishing your goal.
Slate's attempt to track gun-related homicides is one such spreadsheet-based do-it-yourself data project. For this quick walkthrough, we're going to track the places we like to eat.
If you find spreadsheets incomprehensible, you're in good company that includes even the warden of Rikers Island, one of the world's largest prisons.
From the New York Times, "Report Found Distorted Data on Jail Fights at Rikers Island"
When interviewed by correction investigators on May 14, 2012, Mr. Clemons said he rarely reviewed reports on daily inmate fights, according to the audit. Though the data was delivered to him electronically, he said he found the spreadsheets difficult to read on his computer and could not figure out how to print them. He told investigators he had no reason to question the accuracy of the data, in part because he had “noticed fewer alarms over the course of his tenure,” the report said.
Mr. Gumusdere told investigators that he had difficulty understanding the incident reports and rarely reviewed them. He said he delegated this to his subordinates, whom he described as “incompetent,” according to the audit.
So why spreadsheets? They're not that difficult. And with minimal effort, an otherwise plain list becomes data that can be easily analyzed and extended.
Basically, every non-trivial application has a spreadsheet (or something like a spreadsheet) behind it. Because computers like structured information.
I asked the class to provide a CSV of their favorite restaurants, in this format:
name,address,city,state,category,yelp_url
Shake Shack,E 23rd St and Madison Ave,Manhattan,NY,Burgers,http://www.yelp.com/biz/shake-shack-new-york-2
Big Gay Ice Cream,125 E 7th St.,Manhattan,NY,Desserts,http://www.yelp.com/biz/big-gay-ice-cream-shop-new-york
Crif Dogs,113 St. Marks Place,Manhattan,NY,Hot dogs,http://www.yelp.com/biz/crif-dogs-new-york
If I had asked the class to just write up a list of their favorite restaurants, I would've received 20 files (likely in varying formats: Word documents, text files, HTML, etc) with no easy way to combine them, e.g.
In-N-Out Burger on Radford in North Hollywood
Chucky Cheese: 1920 Rodeo Dr., Los Angeles
New York Fried Chicken, in New York, on 62 1st Ave, 10001
With everyone following the same format, though, I was able to quickly combine all 20 plaintext files and import them into a nice spreadsheet:
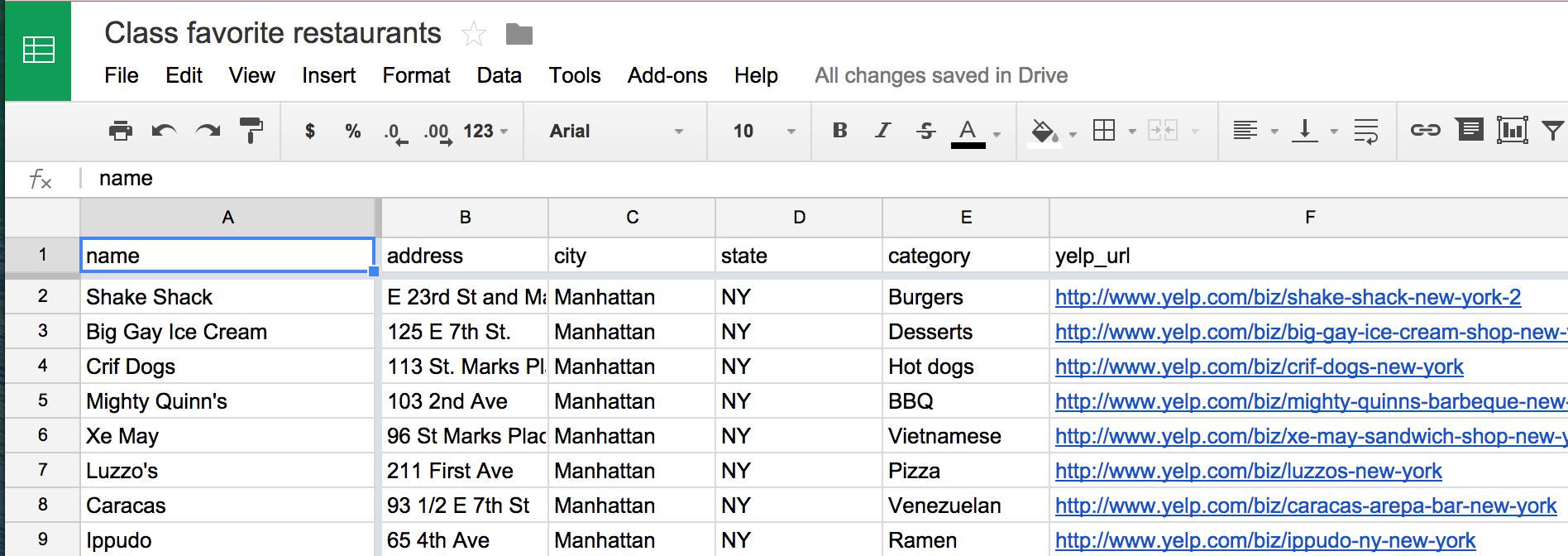
Spreadsheet programs simply know how to turn CSV format (and other delimited text files) into a user-friendly spreadsheet. It doesn't matter that it started out as just plain text.
The main takeaways from manually creating CSV files is that:
If we tell a spreadsheet program that we're importing a CSV file, i.e comma-separated values, then it will expect the data in that text file to be separated by commas.
So if your CSV file is a little awry:
name,address,city,state,category
McDonalds,100 Broadway,New York NY,Burgers
Taco Bell,200 Smith St,Building 4,Chicago,IL,Tacos
In-N-Out near 600 Palm Drive in Santa Monica, Burgers
You're going to get an awry spreadsheet:

So keep in mind this power of typos and how even a single character can wreck a computer's ability to do analysis.
One of the problems with all kinds of data is knowing when two names refer to the same thing. For example:
| name | address | city | state | category |
|---|---|---|---|---|
| Momofuku | 171 1st Ave | New York | NY | Ramen |
| Momofuku Noodle Bar | 171 1st Ave. | New York | NY | Asian Fusion |
It does appear to be the same restaurant, since the address is the same. But again, remember that a single character will throw off a computer's calculations. In other words, "Ave" is not equal to "Ave.", as far as the computer is concerned, and thus, the computer will consider these two records to refer to two different restaurants.
This is a common problem in data work, hence, the term "dirty data" and the valuable skill of "data cleaning".
However, with the Yelp URL, we (kind of) sidestep the issue of needing the names and addresses to be exact. As long as there is just one Yelp entry for both of the Momofuku listings, e.g.
http://www.yelp.com/biz/momofuku-noodle-bar-new-york
Then we can tell the computer to use that when grouping (e.g. to count up entries for a pivot table) the records and be reasonably confident that it can determine duplciate entries.
Another benefit of including the Yelp URL is that we can quickly add useful Yelp data to our class crowdsourced list, such as whether Yelp users liked the restaurants as much as we do, how many Yelp users have patronized the restaurants, and how expensive each restaurant in the eyes of the Yelp userbase.
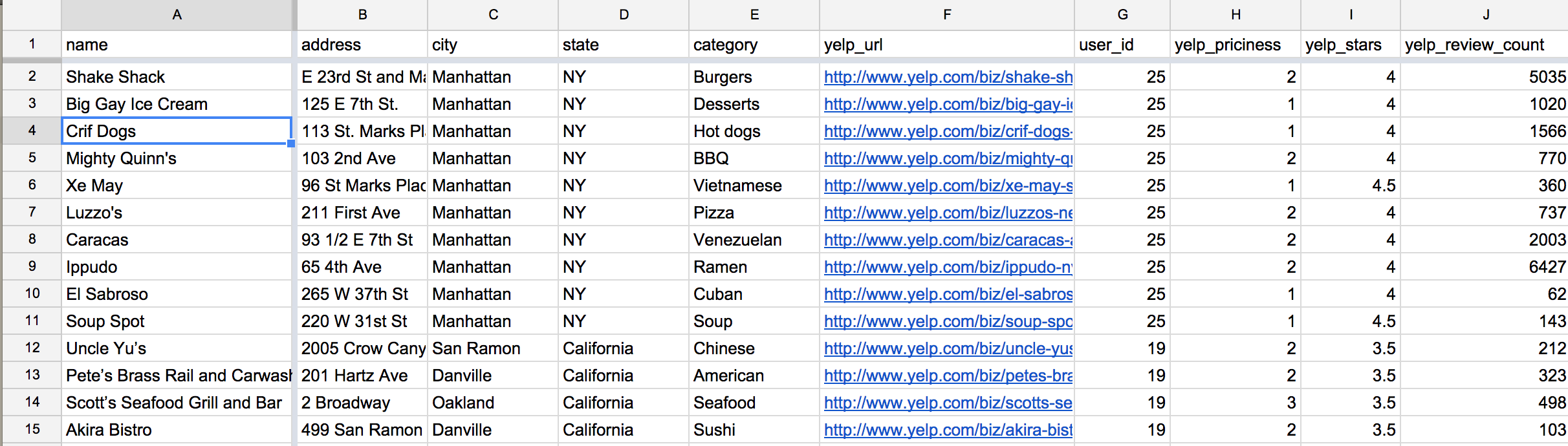
Note: in the class spreadsheet, I've also added a "user_id" field, which is a random number given to each class member, just so we can pivot on that value and evaluate each individual's taste. Keep reading to see the results of that.
Check out the full class spreadsheet here on Google Drive.
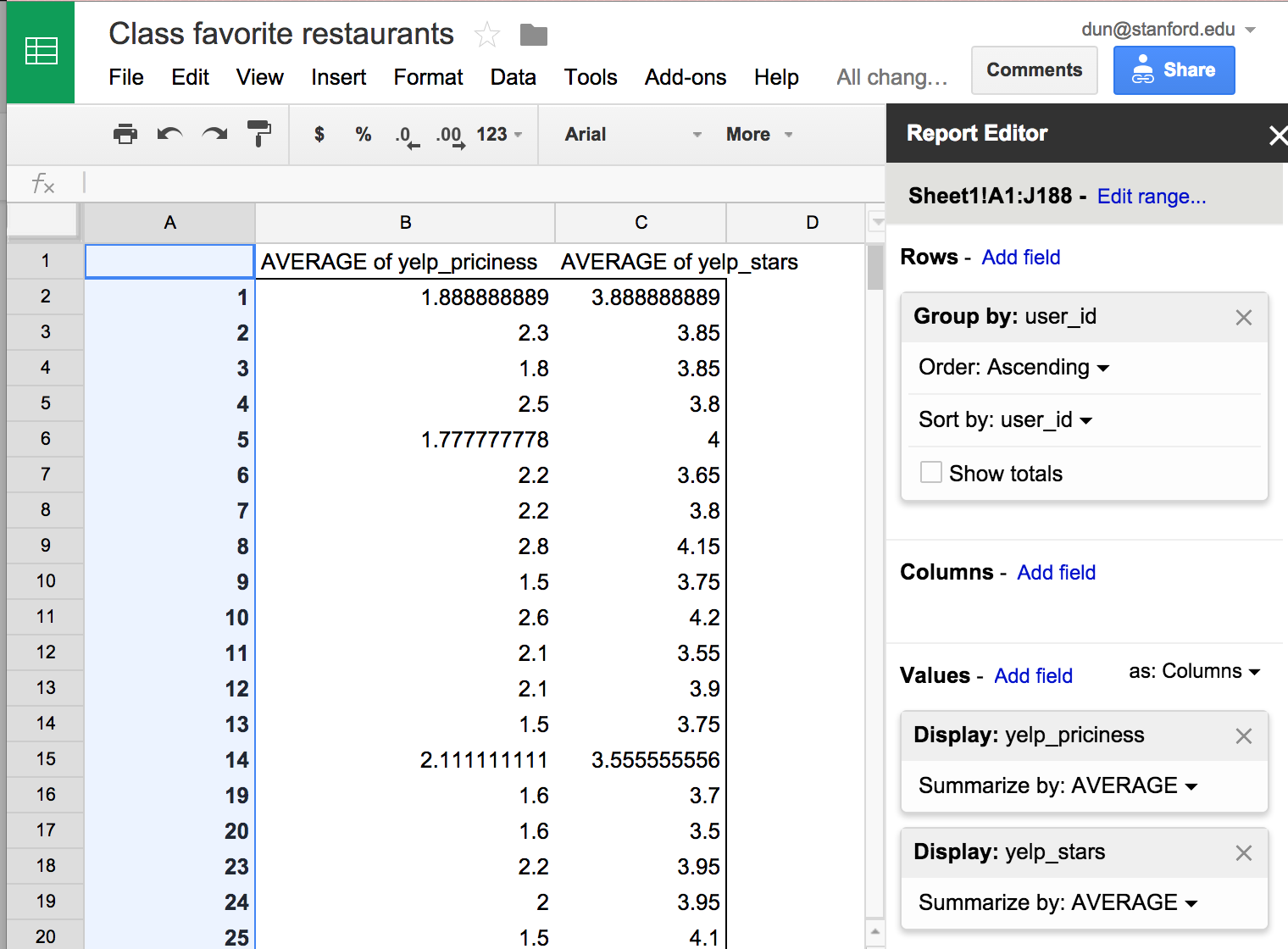
With this restaurant list in a spreadsheet, we can try all kinds of interesting pivots. For example, by grouping rows by user_id, we can then analyze:
state, the states/countries each of us have lived in or traveled to.yelp_stars, how each of us agreed or differed with the Yelp crowd in terms of tasteyelp_priciness, how extravagant each of us are in our favorite restaurants.We could also pivot starting with state, to see total number of favorite places per state, or the average priciness of good places to eat (does New York have higher Yelp priciness ratings compared to Texas)? And so forth.
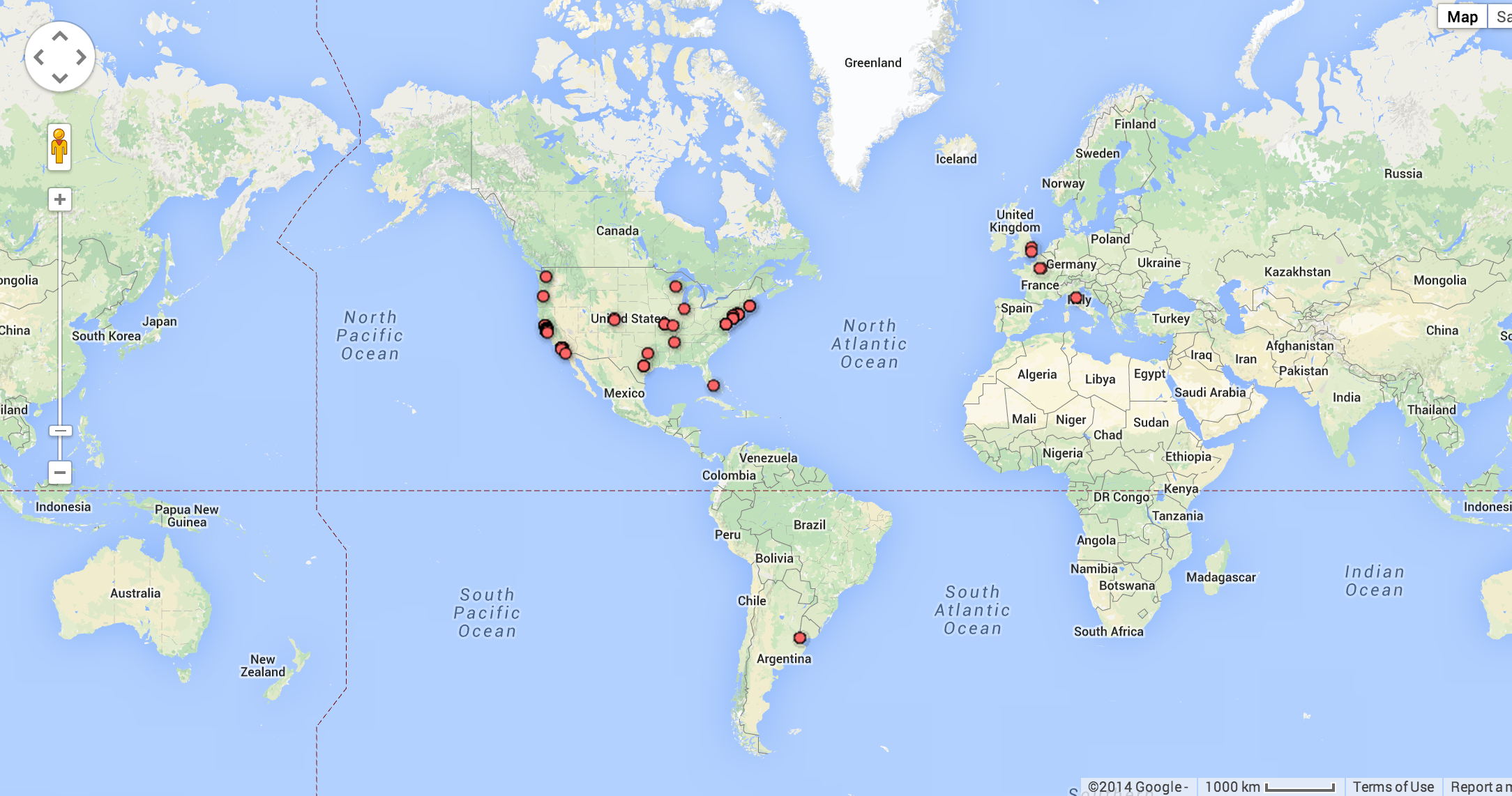
Since we took the time to record the addresses of each place (which we could've derived from the Yelp listing, but I wanted this assignment to include a bit of manual labor), we now have the potential to map this data.
There are many ways to geocode and display address data. Google Fusion Tables is a convenient service, and as I mentioned earlier, it is basically just a spreadsheet. In fact, we can import our current spreadsheet directly into Fusion Tables.
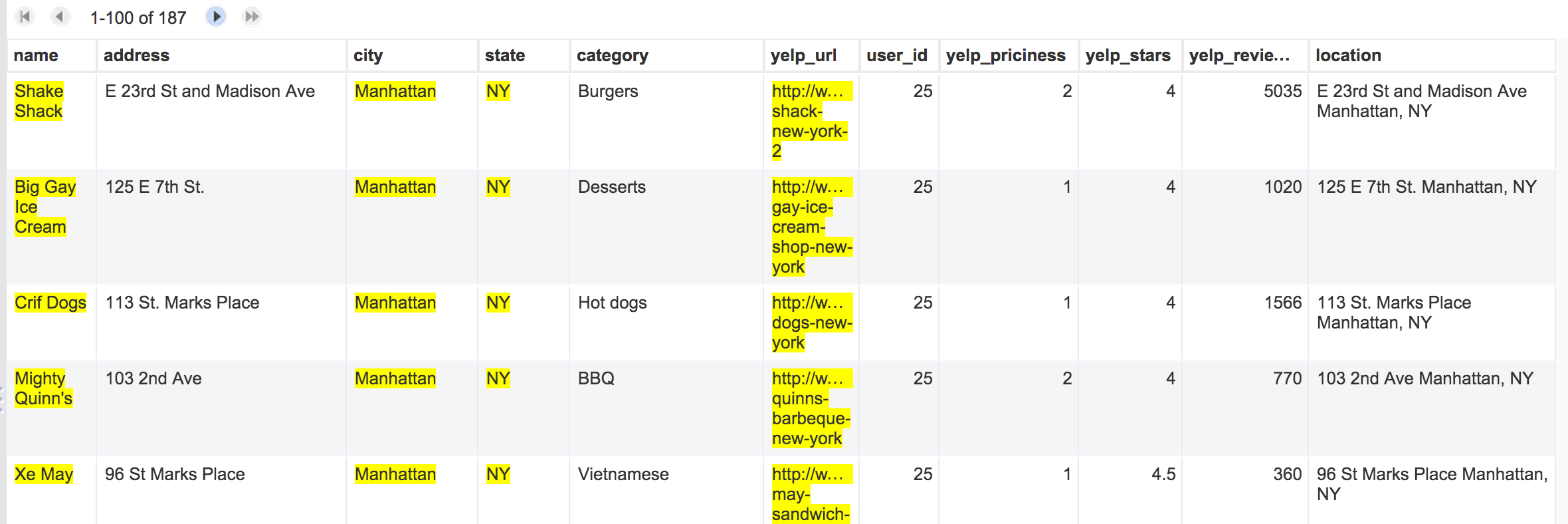
There is one convention we have to follow, though: Fusion Tables wants a single column against which it can look up geo-coordinates. We currently have three: address, city, state.
This is easily fixed in the spreadsheet by creating a new column (which you can name location) and then filling it with a formula like this:
=CONCATENATE(B2, " ", C2, ", ", D2)
Which will produce a string like this:
E 23rd St and Madison Ave Manhattan, NY
I won't cover the details of how to use Fusion Tables, though you can see the results at this link.
Here's what a Fusion Table looks like (again, basically a spreadsheet):
Here's how Google maps our location field:
Another potentially useful column is category. For example, it'd be interesting to see how many of us like Sushi places versus French places. However, a quick pivot using category as the Rows shows it's a little more complicated than that:
American 19
American (New) 2
American Diner 1
American Pub 1
American Steakhouse 1
American(Traditional) 1
Should all of those be "American"? What about the five things categorized as "Burgers"?
Another categorical quandary:
| name | address | city | state | category |
|---|---|---|---|---|
| Buffalo Wild Wings | 1620 Saratoga Ave | San Jose | CA | American |
| Buffalo Wild Wings | 505 E Nifong Blvd | Columbia | MO | Chicken Wings |
Is Buffalo Wild Wings really just "Chicken Wings", or is it so much more, considering their offerings of chicken sandwiches and "Cheeseburger Slammers"? And maybe "American" is too broad, perhaps it should be considered a "Bar & Grill"?
This is the problem of taxonomy, and it's not easily solved other than having a sort of discipline and "style guide" to resolve these ambiguities. One strategy is to just make more columns, such as category and subcategory, though that adds even more work and more ways for people to differ on the exact genre of Buffalo Wild Wings.
While spreadsheets aren't the perfect all-encompassing data tool, getting into the habit of using them to not just store numbers, but lists and notes, will make it much easier to create data that can be analyzed and extended into interesting visualizations and applications.
A short readable guide to one of the most vital and fundamental data journalism tools.