The Uber effect
In June 2010, the Uber ride-sharing service launched in San Francisco. Besides changing our transportation habits, and the bottom-line of existing cab services, Uber believes it has also had a profound effect on public safety.
From their blog: DUI rates decline in Uber cities
We estimate that the entrance of Uber in Seattle caused the number of arrests for DUI to decrease by more than 10%. These results are robust and statistically significant. The diagram below illustrates the “Uber effect” relative to the baseline of DUIs.

…Uber is responsible for approximately -.7 DUIs per day, or more than a 10% reduction overall. However, this approach is inherently weakened by the fact that many things could have caused DUI to go down around the time when Uber entered. In order to test the robustness of this estimate, we use San Francisco as a control city in a “differences-in-differences” framework. The result is consistent:

The Washington Post's Wonkblog took a second look (and included Lyft's entrance) at San Francisco and concluded that more research was needed, but the raw numbers don't seem to contradict Uber's claims. The WaPo produced this chart from SF DUI numbers:

Counter-claim: It's all about the policing
Some law enforcement officials remain skeptical, SCPR.org reported:
Seattle Police Detective Drew Fowler said Uber shouldn’t be taking credit for reducing DUIs.
“We have seen a decrease in the number of DUI arrests made," Fowler said. "If part of that can be assigned to the introduction of Uber, fantastic. But I don’t think proving the veracity of that is going to be very easy to do.”
Fowler said it's more likely that DUIs have fallen because of a crackdown on drunk driving as part of a statewide initiative called Target Zero.
Sometimes crime numbers drop because there are fewer police to make reports. Here, the Seattle detective thinks an increased police presence drove down DUI rates.
And it always pays to remember: Correlation does not equal causation. It seems intuitive that Uber would allow more people to get home drunk without driving. But maybe those people stayed home before Uber was around, due to the inconvenience of having to find a ride home otherwise. Maybe Uber's real effect is that more people get to party who otherwise wouldn't – which is not a bad feat, by mind you.
Let's make a pivot chart!
So what's the truth? Finding all the datasets across the different domains (such as number of liquor sales and bar business over time) is beyond our ability. But one thing we can do is just verify just one piece of Uber's evidence, something that's well within our means: the DUI reports in San Francisco.
The big picture: We want to re-create the Washington Post Wonkblog's chart; But we need to get the data in the right form. In fact, much of your difficult work in visualization (or any analysis) will be to get the data in the right form for whatever chart-making tool you're using.
We start out with a spreadsheet with every DUI report in the San Francisco crime incident database. Every report has its own row, and we may be able to count the total number of incidents (by counting up all the rows), but we can't figure out how many incidents there are by, say, per month and year:

We need a thing that looks like this: A row for every month-year combination, and a column that counts number of incidents that have that month-year

And then we can chart it.
As an exercise, let's first chart the rate of DUIs by hour.
- Open Google spreadsheet
- Make a copy
- Add some frozen panes, stretch out some fields
- Add a column to the end of the sheet and name it
hour -
Add the formula
=HOUR(E2)(assumingEis thetimecolumn) and calculate the formula down all the rows.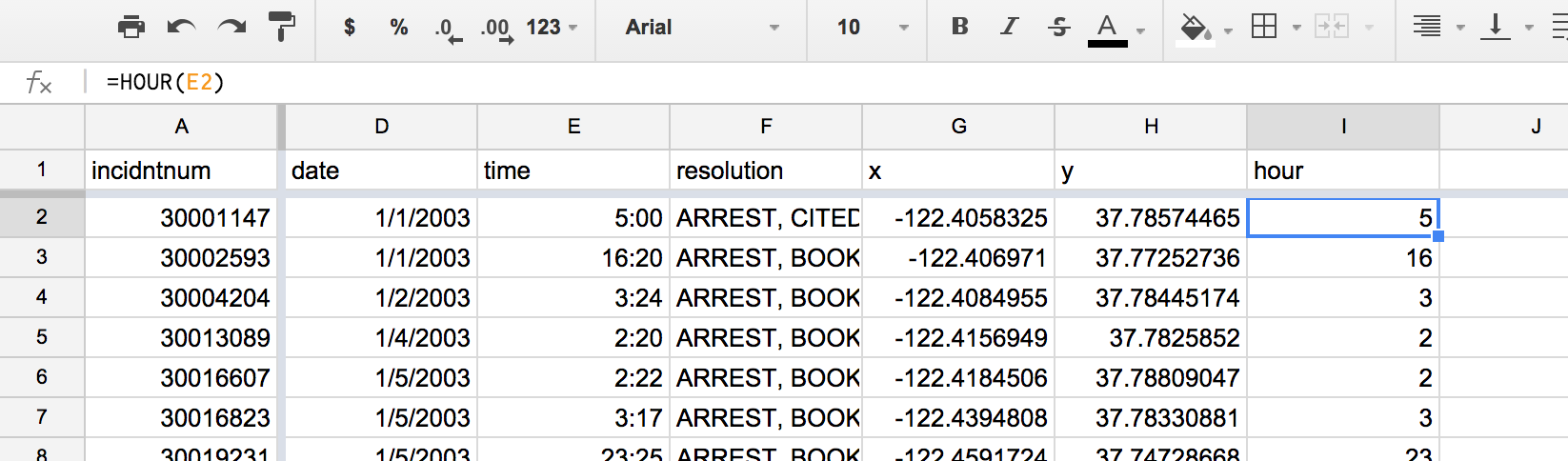
- Now make a Pivot Table
-
For the Rows editor, we want to Group by: hour (you can uncheck the Show totals box, too). This ennumerates all the possible values in the
hourcolumn, i.e.0(midnight) to23(11PM):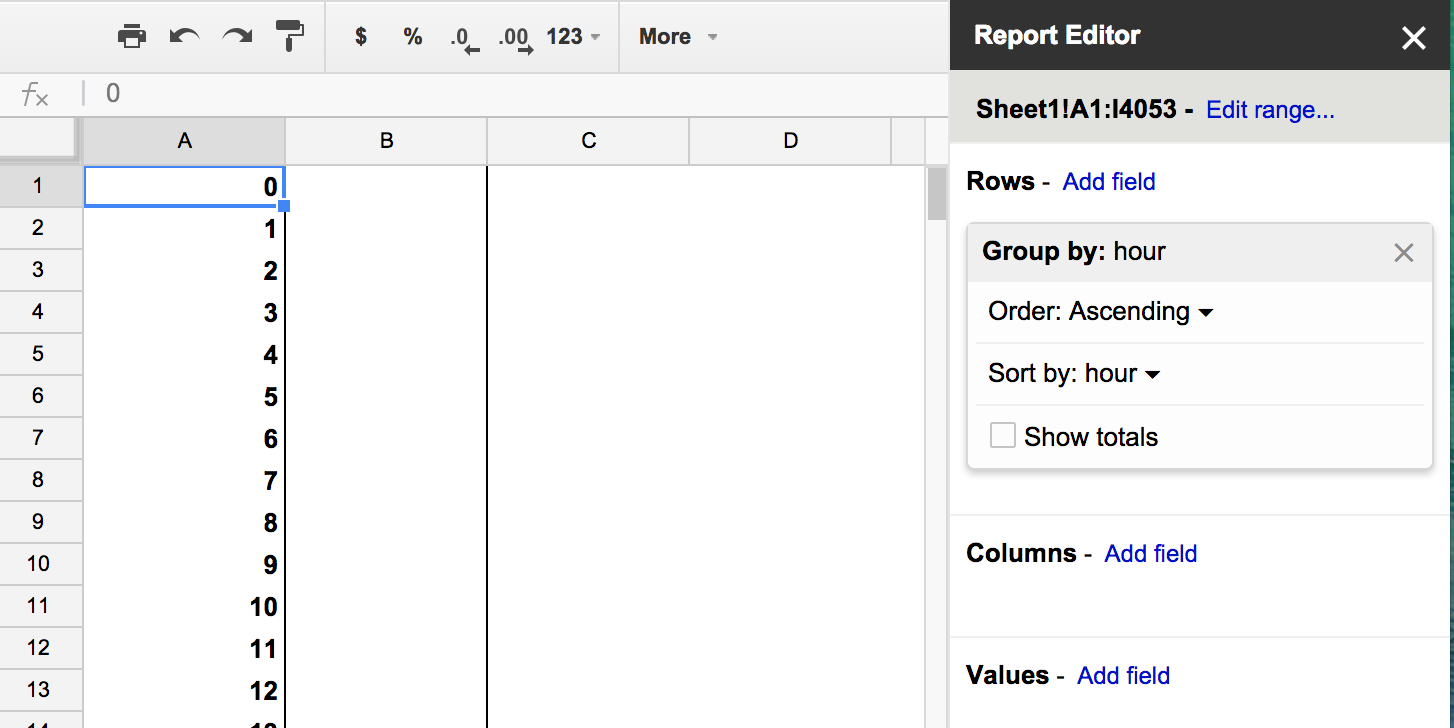
-
Now we need to create a second listing in our pivot table: how many DUIs were reported per hour; in other words, the kind of summary we want is a count of the rows. So in the Values section, it doesn't matter what column you pick out. But for consistencies' sake, just pick
incidntnum. -
By default, the pivot table will try to Display the SUM of the incident numbers…which makes no sense for what we want to do. Change the Display option to COUNT
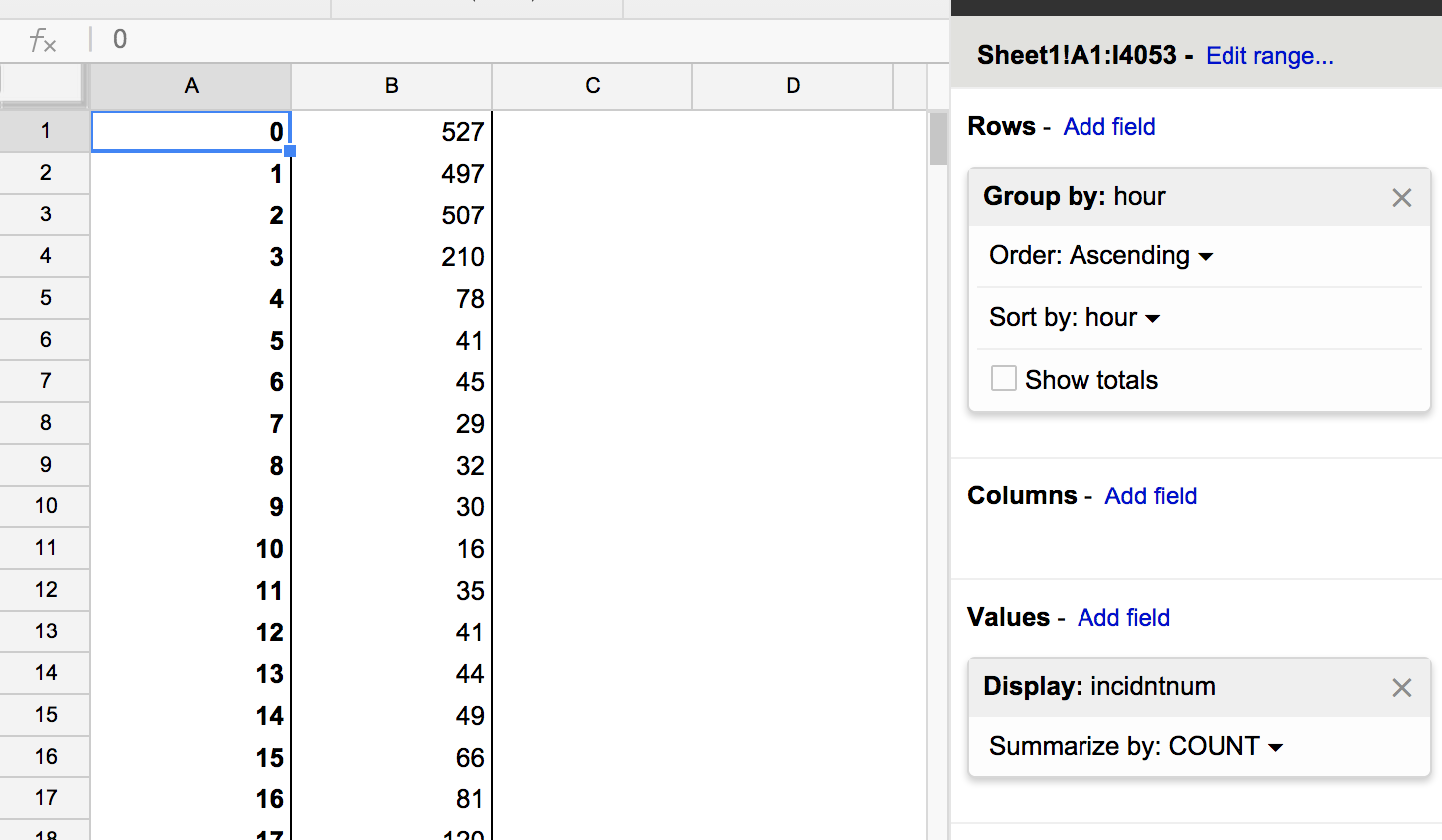
- To visualize this, we select from the menu: Insert a new Chart. Check the Use column A as labels (remember that the first column has what will be the hour labels) and select the Line chart (Google Charts may recommend a few irrelevant chart types at first):

As expected, based on Uber's findings, people tend to get caught driving drunk in the night (and comparatively rarely during, say, 10AM).
Let's move on to our original goal: charting by month and year.
DUIs by month and year
Return to the original sheet (it should be called "Sheet1" in the bottom tabs) and now add a new column: year_and_month.
We want the values in this column to be a combination of the year and month derived from the date column. This can all be done in one formula:
=TEXT(D2,"YYYY-MM")
This is an admittedly esoteric-looking formula…but it's important because we need to extract just the year and the month so that we are summarizing (i.e. counting) incidents per year and month, and not by each day. The new column will look like this:
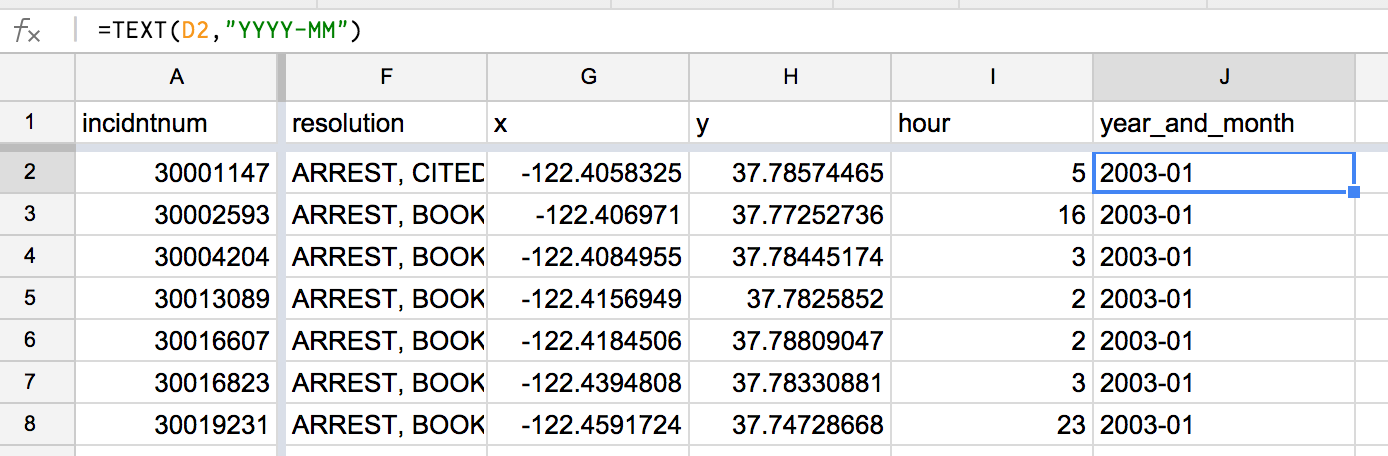
You can either make a new pivot table, or return to the previous one. If you do the latter, you have to Edit [the] range since we've added a new column to the report.
Now, when you Add field to Rows, the year_and_month option should show up.
Select that. And then for Values, again pick a column and choose Summarize by: COUNT
The pivot table will now look like this:
And then insert a new chart as before to get something pretty similar to what the WaPo Wonkblog has:

Simplifying the data
In the Wonkblog piece, they note a curious trend in both the SF and Philly DUI numbers:
It's also striking that San Francisco and Philadelphia show a steep and parallel rise in DUIs long before these services ever came to town; on both charts, it looks as if DUI numbers may be returning to an older normal as much as they've been falling. Perhaps these services have arrived on the market just in time to ride the benefits of an improving economy? (More theories on this welcome below as well).
Let's make some theories of our own. We can't do anything for Philly right now, but let's check out our SF numbers. Eyeballing the chart, it seems like the spike happened somewhere between 2008 to 2009 (Uber launched in June 2010)
The problem with our current pivot table is there's too much data. So go back to the original spreadsheet and add two more columns, just year and month (you can figure out the formulas yourself). Then re-adjust your pivot table to include those columns.
Let's make a simpler chart: Instead of grouping the Rows by year_and_month, simply group by year and make a column chart of the results:

2009 seems like a banner year for DUI reports. Let's look even closer at that number by examining the data at a monthly level.
Crosstab across year and month
So far, we've been using the pivot tables in the simplest way: to aggregate across one dimension (counting incidents per hour, for instance). But pivot tables are especially useful for multiple dimensions, such as incidents per year, per month.
Well, we kind of did that with the "year_and_month" field, but that only generated a two column chart. You'll see the difference in what I mean if you do the following:
- In the Rows section of the Report Editor, change the Group by field to the
yearcolumn. - In the Columns section, add the
monthfield. - Set the Values as before
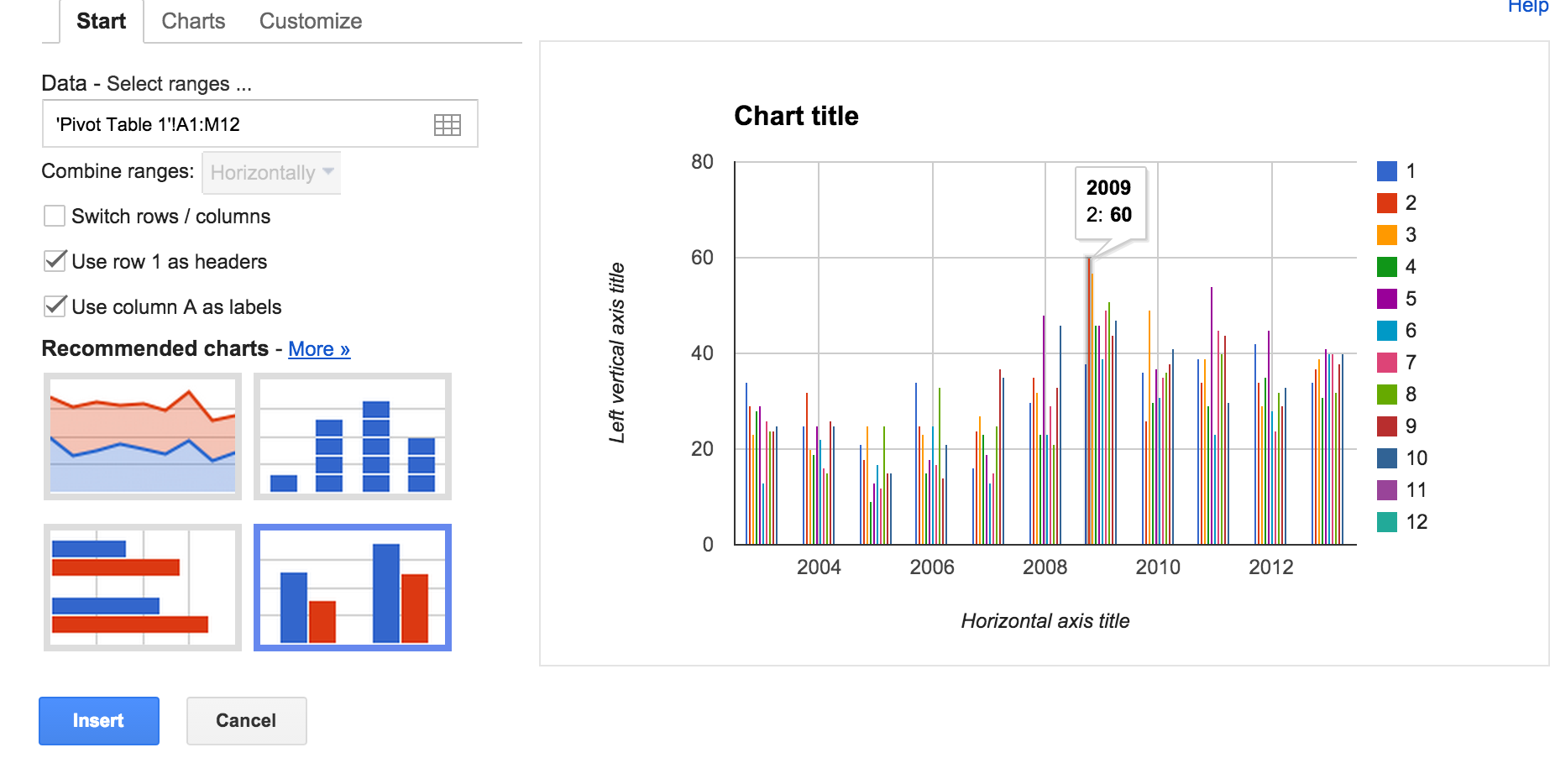
You'll now get a nice cross-tabulation of the data:

Notice anything strange? In February 2009 (the column headed by 2), there were 60 DUI reports. In February 2008 and 2010, there were 35 and 26 incidents respectively. Make a chart of this pivot table to see the difference visually:
In the assignment, you'll practice the use of Pivot Tables. I've posted a complete walkthrough for the assignment here.