Previous tutorials
Using SQL Joins to Analyze a Year of Baby Names and Gender Trends – A walkthrough on how to create and fill new tables, and then a review of INNER and LEFT joins.
I wrapped up the last lesson by pondering how nice it would be to have a SQL table – built from the babynames data – that made it much easier to predict a person's gender based on their first name. I also said we should call it the genderizer.
In this lesson, we build the genderizer, one SQL query at a time.
genderizer tablegenderizer tablegenderizer table
genderizer table to usegenderizer tableUsing the babynames table that we started out with, this is how I would use it to find out if "Dakota" was more likely to belong to a boy or a girl (at least when the 1990 data came out):
SELECT *
FROM babynames
WHERE name = 'Dakota'
ORDER BY babies DESC;
| name | sex | babies |
|---|---|---|
| Dakota | M | 1549 |
| Dakota | F | 380 |
We can eyeball these results and do the math: 100 * 1549 / (1549 + 380) results in an answer of roughly 80%, i.e. 80 percent of babies named Dakota are male, at least in 1990.
OK, seems easy enough. But what if I have to look up hundreds of names and determine which are probably male and which are probably female? That simple SQL query and mental math is going to get rough. Certainly, it's not going to scale across tens of thousands of names.
Instead, we want a table as easy to use as this:
SELECT *
FROM genderizer
WHERE name = 'Dakota';
| name | gender | ratio | total_babies |
|---|---|---|---|
| Dakota | M | 80 | 1929 |
If you can't see how this can easily be joined against any other kind of table, that's fine…but at least you can see how genderizer returns an easy-to-digest single row.
A few things to note:
gender the name indicates the most likely gender, e.g. M or Fgenderizer has a ratio column, which represents what percentage of babies belong to the corresponding most-likely gender.total_babies column is there for the user to figure out the statistical significance any way they like.And to keep things simple and consistent with the florida_positions table – remember that table? We're about to return to it – we should also uppercase the names.
Sound good? Let's build it out of pure SQL and (simple) math.
genderizer tableYou know how to create a table in SQL by now, so try to think what the statement looks like before seeing the scheme that I propose below:
CREATE TABLE "genderizer"(
"name" VARCHAR,
"gender" CHAR,
"ratio" INTEGER,
"total_babies" INTEGER
);
(Again, specifying VARCHAR and CHAR are totally optional for SQLite…you could just as well use TEXT – I do it out of habit from using MySQL for so long…)
genderizer tableObviously, we're going to re-use that INSERT INTO statement that we learned in the last lesson – there's no point in further explaining it…it just works, when it comes to transferring data between exiting SQLite tables.
But from what SELECT statements do we use? In my mind, it's simplest to not do one statement, but four separate INSERT INTO and SELECT queries to fill out the genderizer table:
LEFT JOIN from girlnames to get girl-only namesLEFT JOIN from boynames to get boy-only namesINNER JOIN with boynames and girlnames, then filter for names in which there were equal or more girl than boy babies.INNER JOIN with boynames and girlnames, then filter for names in which there were more boy than girl babies.Let's go through each of these queries.
We did this in the previous lesson. See if you can recall it without looking at the previous example.
Here's a hint: we need to start with selecting FROM the girlnames table.
And here's the query:
SELECT
girlnames.name,
girlnames.babies
FROM girlnames
LEFT JOIN boynames
ON boynames.name = girlnames.name
WHERE boynames.name IS NULL;
| name | babies |
|---|---|
| Breanna | 2952 |
| Katrina | 2479 |
| Alisha | 2343 |
| Grace | 2186 |
| Krista | 2143 |
Remember that the schema for genderizer contains four columns:
"name" VARCHAR,
"gender" CHAR,
"ratio" INTEGER,
"total_babies" INTEGER
These columns are easy to calculate because of the nature of our LEFT JOIN, in which we know that all of the names returned are exclusively female:
This means that gender can just be set to 'F'. If you remember back to an early lesson about SQL, we can arbitrarily include constant and literal values in a query results:
SELECT
boynames.name,
'hello world',
'whatever' AS gender,
42 AS "ANSWER TO LIFE",
'?' AS "༼◕_◕༽"
FROM boynames
LIMIT 3;
| name | ‘hello world’ | gender | ANSWER TO LIFE | ༼◕_◕༽ |
|---|---|---|---|---|
| Michael | hello world | whatever | 42 | ? |
| Christopher | hello world | whatever | 42 | ? |
| Matthew | hello world | whatever | 42 | ? |
In terms of ratio, if we know these names were given only to females, then the female ratio of that name is 100%.
And of course, this means that total_babies is just equal to girlnames.babies, as there are no boy babies with these names.
Here's the query, basically unchanged except for the additional, aliased columns:
SELECT
girlnames.name AS name,
'F' AS gender,
100 AS ratio,
girlnames.babies AS total_babies
FROM girlnames
LEFT JOIN boynames
ON boynames.name = girlnames.name
WHERE boynames.name IS NULL;
| name | gender | ratio | total_babies |
|---|---|---|---|
| Breanna | F | 100 | 2952 |
| Katrina | F | 100 | 2479 |
| Alisha | F | 100 | 2343 |
| Grace | F | 100 | 2186 |
| Krista | F | 100 | 2143 |
See if you can figure this out on your own. It requires just a few changes to the LEFT JOIN we did for girl-only names.
(If you don't get it, I provide the answer later in this lesson).
Selecting for common values in two different tables requires the INNER JOIN.
The syntax is largely the same as the LEFT JOIN, except use INNER instead of LEFT, of course. The following inner-join query returns the names common to both boynames and girlnames:
SELECT
girlnames.name,
girlnames.babies
FROM girlnames
INNER JOIN boynames
ON boynames.name = girlnames.name;
| name | babies |
|---|---|
| Jessica | 46466 |
| Ashley | 45549 |
| Brittany | 36535 |
| Amanda | 34406 |
| Samantha | 25864 |
I've decided arbitrarily to designate names that were split evenly between boys and girls as "female". So we use the greater-than-or-equal operator in the WHERE condition, i.e. >=:
SELECT
girlnames.name,
girlnames.babies
FROM girlnames
INNER JOIN boynames
ON boynames.name = girlnames.name
WHERE girlnames.babies > boynames.babies;
genderizerAgain, the literal value, 'F', can be passed into the gender column.
The total_babies value is the sum of boynames.babies and girlnames.babies.
As far as ratio, this is only slightly more complicated: it's the result of multiplying 100 by girlnames.babies and dividing the result by total_babies, though we have to explicitly restate that calculation, i.e. we can't refer to total_babies and must re-add boynames.babies with girlnames.babies.
Nothing else about the query changes:
SELECT
girlnames.name,
'F' AS gender,
100 * girlnames.babies /
(girlnames.babies + boynames.babies) AS ratio,
girlnames.babies + boynames.babies AS total_babies
FROM girlnames
INNER JOIN boynames
ON boynames.name = girlnames.name
WHERE girlnames.babies >= boynames.babies;
| name | gender | ratio | total_babies |
|---|---|---|---|
| Jessica | F | 99 | 46606 |
| Ashley | F | 99 | 45788 |
| Brittany | F | 99 | 36647 |
| Amanda | F | 99 | 34502 |
| Samantha | F | 99 | 25922 |
Now we're ready to add these "mostly-female" names to the genderizer table.
Again, see if you can figure this out on your own, it's very similar to deriving the mostly-female names. If you don't get it, I provide the answer below
OK, let's add the data to genderizer. Since it's so long since we last looked at the table schema, we might as well DROP it (if it still exists), re-create it, and then run the queries described above.
genderizer tableDROP TABLE IF EXISTS "genderizer";
CREATE TABLE "genderizer"(
"name" VARCHAR,
"gender" CHAR,
"ratio" INTEGER,
"total_babies" INTEGER
);
First, the boy-only names:
INSERT INTO "genderizer"
SELECT
boynames.name AS name,
'M' AS gender,
100 AS ratio,
boynames.babies AS total_babies
FROM boynames
LEFT JOIN girlnames
ON boynames.name = girlnames.name
WHERE girlnames.name IS NULL;
Then the girl-only names:
INSERT INTO "genderizer"
SELECT
girlnames.name AS name,
'F' AS gender,
100 AS ratio,
girlnames.babies AS total_babies
FROM girlnames
LEFT JOIN boynames
ON boynames.name = girlnames.name
WHERE boynames.name IS NULL;
First, the mostly-boy names:
INSERT INTO "genderizer"
SELECT
boynames.name,
'M' AS gender,
100 * boynames.babies /
(girlnames.babies + boynames.babies) AS ratio,
girlnames.babies + boynames.babies AS total_babies
FROM girlnames
INNER JOIN boynames
ON boynames.name = girlnames.name
WHERE boynames.babies > girlnames.babies;
Then the mostly (or at least 50%)-girl names:
INSERT INTO "genderizer"
SELECT
girlnames.name,
'F' AS gender,
100 * girlnames.babies /
(girlnames.babies + boynames.babies) AS ratio,
girlnames.babies + boynames.babies AS total_babies
FROM girlnames
INNER JOIN boynames
ON boynames.name = girlnames.name
WHERE girlnames.babies >= boynames.babies;
Remember that the florida_positions table has a FirstName column, and that all the names are uppercased. To simplify our JOIN statements – i.e. to avoid having to repeatedly write UPPER(genderizer.name) = ... – let's use an UPDATE statement to uppercase all of the values in name.
Sure, I could create a new column just to be safe…but we know that every name in the Social Security Administration's database is capitalized in the same way, i.e. it's easy to reverse our changes:
UPDATE genderizer
SET name = UPPER(name);
That was a lot of code we just copy-pasted/retyped, which means there is a lot of possibility for human error – think fatigue or clumsy fingers – and for the kind of errors that don't get caught by the SQLite interpreter.
The very least we can do is confirm the counts that we got in the previous lesson
| name count | total babies | |
|---|---|---|
| All | 22,674 | 3,950,252 |
| Boy & girl names | 2,039 | 3,198,292 |
| Boy-only names | 7,443 | 257,039 |
| Girl-only names | 13,192 | 494,921 |
Here are the queries to do so; you can run them yourself:
SELECT
COUNT(*) AS all_name_count,
SUM(total_babies) AS all_total_babies
FROM genderizer;
SELECT
COUNT(*) AS mixed_sex_name_count,
SUM(total_babies) AS mixed_sex_total_babies
FROM genderizer
WHERE ratio BETWEEN 1 AND 99;
SELECT
COUNT(*) AS boy_only_name_count,
SUM(total_babies) AS boy_only_total_babies
FROM genderizer
WHERE ratio = 100
AND gender = 'M';
SELECT
COUNT(*) AS girl_only_name_count,
SUM(total_babies) AS girl_only_total_babies
FROM genderizer
WHERE ratio = 100
AND gender = 'F';
The results of the queries should equal the values in the table above. At least, they did for me…
genderizer table to useWhew, that was a lot of work. Let's try it out!
Which boy- and girl-only names – i.e. have a ratio of 100 – are the most popular?
SELECT *
FROM genderizer
WHERE ratio = 100
ORDER BY total_babies DESC
LIMIT 5;
| name | gender | ratio | total_babies |
|---|---|---|---|
| BREANNA | F | 100 | 2952 |
| KATRINA | F | 100 | 2479 |
| ALISHA | F | 100 | 2343 |
| RUSSELL | M | 100 | 2213 |
| GRACE | F | 100 | 2186 |
This is an important query, as the names it returns are the ones that have the highest likelihood of misclassifying names. Let's define gender-neutral as a ratio of 55% or less:
SELECT *
FROM genderizer
WHERE ratio <= 55
ORDER BY total_babies DESC
LIMIT 10;
| name | gender | ratio | total_babies |
|---|---|---|---|
| TAYLOR | F | 52 | 13830 |
| CASEY | M | 55 | 7391 |
| JESSIE | M | 52 | 2371 |
| INFANT | M | 50 | 1176 |
| SKYLAR | M | 51 | 866 |
| DEVAN | M | 54 | 708 |
| KRISTIAN | F | 53 | 671 |
| BABY | M | 54 | 498 |
| SHEA | F | 50 | 450 |
| DOMINQUE | F | 51 | 409 |
There are some pretty common names – Taylor especially – and of course, good 'ol Infant.
Let's expand the definition of gender-neutral to include a ratio as high as 75%:
SELECT *
FROM genderizer
WHERE ratio <= 75
ORDER BY total_babies DESC
LIMIT 10;
| name | gender | ratio | total_babies |
|---|---|---|---|
| JORDAN | M | 73 | 22082 |
| TAYLOR | F | 52 | 13830 |
| CASEY | M | 55 | 7391 |
| ANGEL | M | 59 | 4067 |
| DOMINIQUE | F | 56 | 3430 |
| DEVON | M | 67 | 3053 |
| JESSIE | M | 52 | 2371 |
| JAIME | M | 61 | 2318 |
| KASEY | F | 74 | 1797 |
| KENDALL | M | 57 | 1508 |
Let's see what names fall within a ratio of 85%:
SELECT *
FROM genderizer
WHERE ratio <= 85
ORDER BY total_babies DESC
LIMIT 10;
| name | gender | ratio | total_babies |
|---|---|---|---|
| JORDAN | M | 73 | 22082 |
| TAYLOR | F | 52 | 13830 |
| JAMIE | F | 83 | 7828 |
| CASEY | M | 55 | 7391 |
| DEVIN | M | 81 | 4723 |
| ANGEL | M | 59 | 4067 |
| DOMINIQUE | F | 56 | 3430 |
| DEVON | M | 67 | 3053 |
| JESSIE | M | 52 | 2371 |
| JAIME | M | 61 | 2318 |
It's worth noting that the origin of the original babynames table will have a major impact. If you followed these tutorials from the beginning, you might remember that babynames consists of baby name data from 1990. Is that representative of the kind of people whose first names we'll attempt to mass-classify?
Here's a query for some gender-neutral names that I didn't see in our previous queries, perhaps because they weren't as popular in 1990:
SELECT *
FROM genderizer
WHERE name IN('JACKIE', 'KIM', 'KELLY',
'LESLIE', 'LOREN', 'MICAH', 'SHAWN');
| name | gender | ratio | total_babies |
|---|---|---|---|
| MICAH | M | 84 | 1389 |
| SHAWN | M | 97 | 5890 |
| KELLY | F | 92 | 8821 |
| LESLIE | F | 90 | 3123 |
| LOREN | F | 63 | 724 |
| JACKIE | F | 63 | 717 |
| KIM | F | 80 | 321 |
Surely, a few readers will be worried that a name such as Leslie can have a ratio as high as 90%…
So just how many names – and babies – have a skewed ratio such that we can be nearly certain that it predicts a person's gender based on first name alone?
Let's run a query that returns a result that can be easily turned into a histogram, i.e. number of names and total babies per value of ratio:
SELECT
ratio,
COUNT(*) AS name_count,
SUM(total_babies) AS total_babies
FROM genderizer
GROUP BY ratio;
| ratio | name_count | total_babies |
|---|---|---|
| 50 | 48 | 3186 |
| 51 | 11 | 1766 |
| 52 | 36 | 17261 |
| 53 | 31 | 2257 |
| … | … | … |
| 95 | 46 | 40946 |
| 96 | 62 | 55065 |
| 97 | 73 | 87515 |
| 98 | 190 | 303397 |
| 99 | 427 | 2429751 |
| 100 | 20635 | 751960 |
We don't even have to graph this to show how many names and babies have a ratio of 97% – more than 85% of the baby count. But let's graph it anyway:
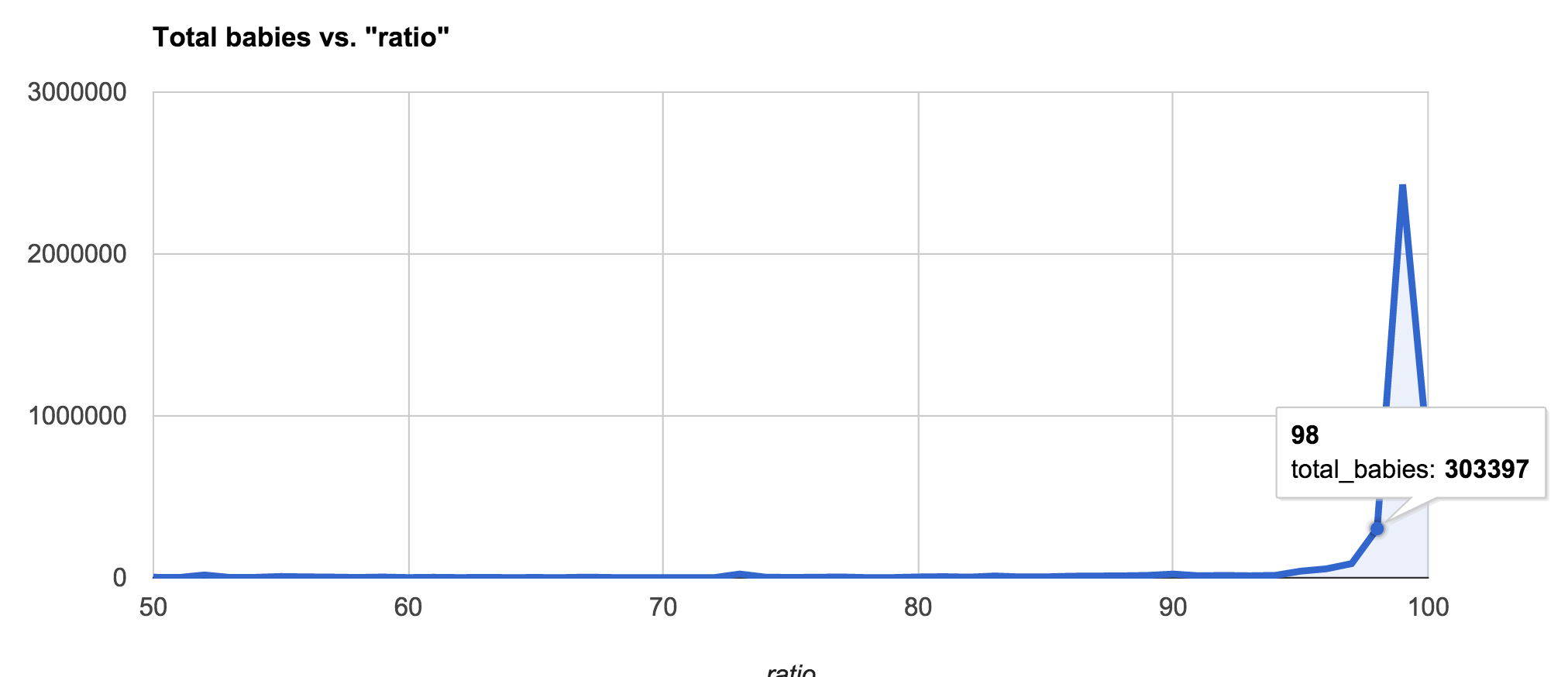
In lieu of more sophisticated statistical analysis, we're going to have a few mistaken classifications – but our genderizer table looks like it'll be mostly right if the names we analyze are not too unusual…