Creating it from scratch
This tutorial walks you through the process of creating tables in a SQLite database and importing data.
I'm assuming you have a copy of the starter database.
Get the data yourself
This is the Social Security Administration baby names data that we've used in previous tutorials, except now you'll see how to create a database from scratch, including the process of downloading the file and importing the relevant text file.
Download the data
From the Social Security Administration homepage, click on the National data file: https://www.ssa.gov/oact/babynames/names.zip
Unzip the file
Unzip the file, it should contain text files for every year, prefixed with yob (i.e. "year of birth"):

Open a text file
Open any one of the text files to see what they contain. For example, this is what the first five lines of yob1990.txt looks like:
Jessica,F,46466
Ashley,F,45549
Brittany,F,36535
Amanda,F,34406
Samantha,F,25864
Besides being reminded that data is often just text, and that this text data is comma-delimited, notice that there are no headers, i.e., if you open yob1990.txt in a spreadsheet, you'll see this:
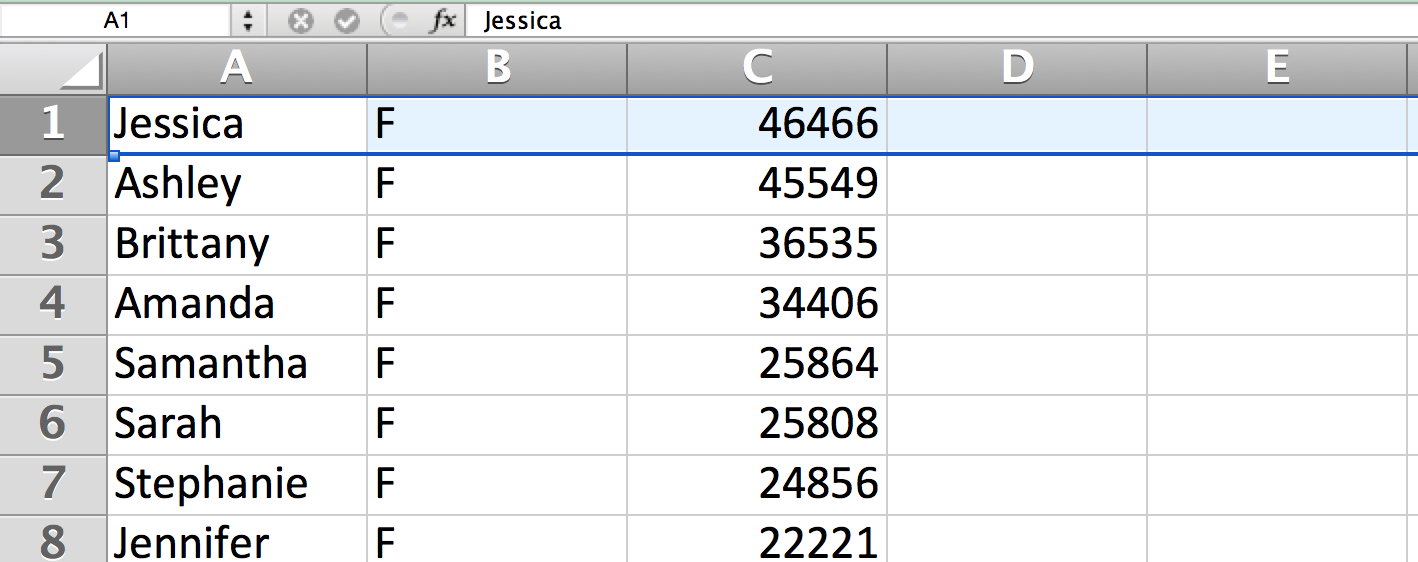
…and that's what the database will see when we try to import one of these text files as is.
Creating a table with the CREATE TABLE statement
In our current database file, we have a table named babynames_2014.
I want to create a new table named babynames_1980 which, as you might guess, will contain the contents of the newly-unzipped yob1980.txt file. Before we can import the text file, we need to create the table and define its structure.
The CREATE TABLE syntax
Creating a new database table requires a whole different syntax than the SELECT statement we've been using…mostlywe are no longer SELECT-ing data.
Instead, we use the CREATE TABLE statement and supply it with a list of column headers and data types:
CREATE TABLE "the_table_name"(
"column_1" DATATYPE,
"column_2" ANOTHER_DATATYPE
);
For our current scenario, we need a table with 3 columns. If you're using the DB Browser for SQLite client, you can click on the Database Structure to see the structure of the babynames_2014 table:

You can guess there's only one thing we need to change for our current purpose. But re-type the CREATE TABLE statement manually, you'll find it it's easier than it seems:
CREATE TABLE "babynames_1980"(
"name" TEXT,
"sex" TEXT,
"babies" INTEGER
);
Then execute it as you would any other query. Refreshing the database structure view should show a new table.
Datatypes
SQLite is pretty laid back about data types. Other flavors of SQL have many kinds of text and number data types. According to the SQLite documentation, there are only 5 official column types. And only 3 of these we currently care about:
INTEGER - basically, whole numbers.REAL - numbers with decimal places.TEXT - Besides holding alphabetical and other kinds of textual characters. Any numbers in a TEXT column are "converted into text form before being stored", though I honestly couldn't tell you what effect that will have in SQLite (other languages are much more pickier)…
More about CREATE TABLE
I don't think we need to focus too much on this right now. We can create tables in SQL, and there's a certain syntax for it. Refer back to the documentation when you need to, but creating tables is a relatively infrequent situation.
The SQLite documentation on creating tables is here, but it may be a bit dense. Basically, the CREATE TABLE statement consists of the name of the table and its schema, i.e. its columns – including the name and the type of data contained in each column.
A typical CREATE TABLE statement consists of these elements:
- The words,
CREATE TABLE.
- The name of the new table; it's best to enclose it in quotation marks
- A pair of parentheses, which encloses a comma-separated list of columns:
- the column name; again, best to enclose it in quotation marks
- the type of the data. For example, if it is an integer (i.e. a whole number), use
INTEGER. Data types, such as INTEGER, TEXT, REAL, and so forth, are semi-special SQL keywords, so you don't have to capitalize them, but you should for easier readability.
Importing a text file into a SQLite database
Now that we've created the table, we can import data to it.
For the remainder of these tutorials, the only time we'll need to use the GUI client – i.e. point-and-click buttons – is for importing data. I recommend this because writing code to handle comma-delimited (or any kind of delimited) text files is a bit complicated. SQLite, the language and database, do not have built-in, robust parsers that we can easily invoke with just SQL code. So it's fine to import-via-GUI; everything else – including creating, dropping, and querying tables – can be done through SQL.
Luckily, DB Browser for SQLite has point-and-click importing – as do other free SQLite clients, such as the Firefox SQLite Manager plugin
The following instructions are for DB Browser for SQLite on Mac, though DB Browser is cross-platform so the steps should hopefully be the same.
In the menubar, click File > Import > Table from CSV…

Select the file to import. For the remainder of this tutorial, I'll be using the yob1980.txt file, i.e. names for babies in 1980. If for some reason you can't get this from the official Social Security Administration site, you can download it from my mirror:
stash.padjo.org/dumps/2015/yob1990.txt
Selecting the text file to import
After selecting the text file to import, the GUI client brings up a new dialog box with a couple of important settings to mind:
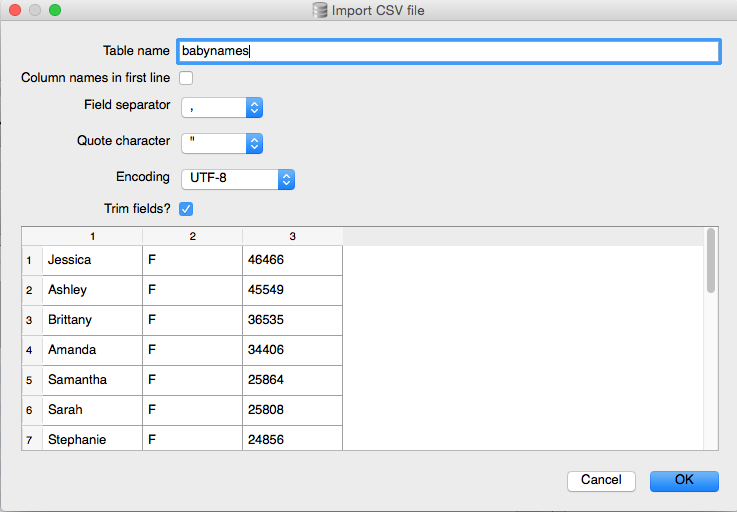
- Make sure the Table name field has the exact name as the name of the table that you had just created, i.e.
babynames
- As we saw when previewing the raw text files, there are no column headers. So uncheck the checkbox titled, Column names in first line, because, the column names aren’t in the first line.
The DB Browser client will ask you if you want to really insert into an existing table. Click Yes.
After the import is finished, you can select the Browse Data view to see the data inside the table.
Note: There's no year column for either of the babynames_2014 or babynames_1980 tables. I've left it out for now because we don't need it for this exercise. We'll get back to it soon, just in case you think it's weird that we have separate tables for different years (it doesn't make much sense to have 150+ tables for each yob.txt file, if their structures are all the same…)
Saving the data in DB Browser
Another note: The DB Browser client, in an attempt to share some familiar user-facing features with Excel, has a feature in which changes we make to the data are not automatically "saved" to file. We have to manually do this by going to the menubar and selecting File > Write Changes.
Or just use the Cmd-S keyboard shortcut.
How to DROP and re-CREATE a table
Before we actually import data into the table, let's pretend we messed up the CREATE TABLE statement and we have a table with misnamed or ill-defined columns. Or maybe we imported the data twice accidentally. As it turns out in SQLite, there's a limited subset of commands we can do to alter/fix an existing table: rename the table or add columns. We cover adding columns in the next chapter – and apparently we can't rename columns.
It's frequently easier just to delete the table and start over. So that's what we'll do with the DROP TABLE statement.
The syntax to drop a table is much simpler than creating one:
DROP TABLE babynames_1980;
Note that in a SQLite GUI client, such as SQLite Browser, you can usually delete a table by right-clicking its name and selecting from a pop-up menu. But if you want to drop a table because you want to immediately re-create it, it's almost always faster to execute the DROP TABLE and CREATE TABLE commands via copy-and-paste:
DROP TABLE babynames;
CREATE TABLE babynames(
"name" TEXT,
"sex" TEXT,
"babies" INTEGER
);
If you want to get fancy, you can throw an IF EXISTS statement which will prevent SQLite from complaining if a table doesn't exist when you try to DROP it. This is a handy feature when you're copying-pasting code and you don't care what the state of the database is beforehand:
DROP TABLE IF EXISTS babynames_1980;
CREATE TABLE babynames_1980(
"name" TEXT,
"sex" TEXT,
"babies" INTEGER
);
Note: If you run a CREATE TABLE query when the table already exists, you'll get an error message. Same thing if you try to drop a non-existent table.
Adding indexes
When tables get large and our searches become more complicated, the time to finish a query may take minutes, hours, or even days.
The act of indexing a table is similar to how and why a book gets indexed: to make it easier to jump to the specific page in which a term is mentioned. Databases need that guidance as well.
There's a lot of technique and computational concepts behind indexing, but I'll review the concepts most pertinent to our current situation.
When do we index a column
If a column is used to filter rows – e.g. in a WHERE conditional clause or JOIN...ON constraint – then it is a candidate to be indexed, because we want the database to be able to search that column efficiently.
So far, our WHERE clauses have looked at the name and sex columns of our database.
The syntax for creating an index
Here's the SQLite documentation for creating an index. But for the most part, you just need to know the syntax:
CREATE INDEX "some_name_of_the_index"
ON "some_table_name"("some_column", "another_column");
To create an index on name for the table babynames_1980:
CREATE INDEX "name_index_on_1980" ON "babynames_1980"("name");
Execute it. And then modify the statement to build an index on babynames_2014.
The importance of cardinality
However, not all searched columns should be indexed. Indexing has tradeoffs. For starters, it increases the physical size of the database – think about the pages that an index occupies at the back of a book.
So why index name but not sex? Because sex has a [low cardinality](https://en.wikipedia.org/wiki/Cardinality_(SQL_statements) of 2. In other words, there are only 2 values for sex: M and F. It's not very hard for the database to filter on sex. But name, on the other hand, has a cardinality in the tens of thousands (i.e. for every unique name). It is worth indexing.
What about babies? There's a lot of cardinality there, but we rarely need to do the specific kind of filtering using babies that we do with name.
Indexing a combination of columns
There's one more nuance to indexing that affects us: if two are more columns are frequently searched on, then we have the option to build an index that combines both columns.
In our baby names situation, we often care about the male versus female entries of a given name, i.e.:
SELECT * FROM
babynames_1980
WHERE name = 'Jordan'
AND sex = 'M';
So even though sex has a low cardinality, we may find it helpful to index name and sex together.
This is what the syntax looks like:
CREATE INDEX "namesex_index_on_1980" ON "babynames_1980"("name", "sex");
The index name just has to be unique in the database, so you can call it "name_and_sex_index_on_1980" or even "1980asdfkljasdfkjl".
How do you know if you've indexed a table properly? To be honest, it won't affect us in the current set of tutorials, as the datasets are relatively small. But depending on the speed of your computer, a query might take up to 10 to 15 seconds on some of this tutorial's queries. An index can reduce that to just a second.
The SQLite documentation has some excellent explanation of the nuances of indexing. However, you just need to be aware of the concept. To have your tables be reasonably optimized for our exercises, just run these example commands:
CREATE INDEX "namesex_index_on_1980" ON "babynames_1980"("name", "sex");
CREATE INDEX "namesex_index_on_2014" ON "babynames_2014"("name", "sex");
In the DB Browser for SQLite Client, you can check the Database Structure tab to see the new indexes:

If you're running into issues, you can download my copy of the database, which has both tables and the indexes.
Testing queries on the 1980 baby names
Any of the queries that worked on the previous lesson will work here on the babynames_1980. Try running through a few of these from memory to see how much different 1980's babynames were compared to 2014.
- How many unique names
- How many names and babies, broken down by sex
- 5 most popular boy names
- 5 longest names with at least 1,000 babies
- 5 most popular girl names that don't end in a vowel
In the next lesson, we'll learn about joins, which will make it much easier to make direct comparisons, e.g. which names were barely in 1980 that are hugely popular in 2014?