Creating a multi-layered QGIS map
Assignment
Deliverables
A map made in QGIS with at least 3 data layers:
- Geographical boundaries
- 2 kinds of point (latitude/longitude) data.
- One of those point-by-point datasets should be turned into a shape layer, like a hexbin.
An example map could be: California school locations (as points), on top of a hexbin layer, which itself sits atop a layer showing the California state boundary.
Create a Folder in your PADJO2015 folder named: PADJO2015-QGIS-MULTILAYERS, and put all relevant project files into that folder. Though you only need the GeoJSON file at the end of it.
Have an exported GeoJSON version of the map you created in QGIS. The end of Michael Corey’s tutorial has an example.
Requirements
Use QGIS to create a map with at least 3 data layers:
One layer should be a boundary shapefile, such as county or city or state boundaries. The Census has a few files.
A second layer should consist of points – i.e. a CSV file with latitude and longitude columns.
A third layer can also be another CSV file. I guess you could use a shapefile and try to intersect it with the other layers, but you’re on your own.
Table of contents
Tutorial
- Download QGIS
- Michael Corey's Advanced GIS tutorial for NICAR
- Be sure to download his example project as a zipped datafile
Data
Boundary data
Point data
- USGS Earthquakes
- California school data
- Fatal encounters data (oops, this data doesn't have latitude and longitude. You can ignore it for now…)
- San Francisco city data portal - 311, crime, and many other things.
Useful background reading
- More than you might ever want to know about map projections, also from Mike Corey
- This is a long dissertation about many other concepts - but it contains a nice interactive map.
My Sample QGIS Triple-Data-Layer Map
The following is an example triple-layer-data map, including a description of what it purports to show, where the data came from, and a brief explanation of the steps, with frequent references to the relevant sections in Mike Corey's QGIS tutorial on earthquakes.
The subject and finished map
For the city of San Francisco, I want to highlight the food carts that are (or aren't) in places where relatively high amounts of drug activity is known to happen. I'll overlay these data points on top of the streets of San Francisco.
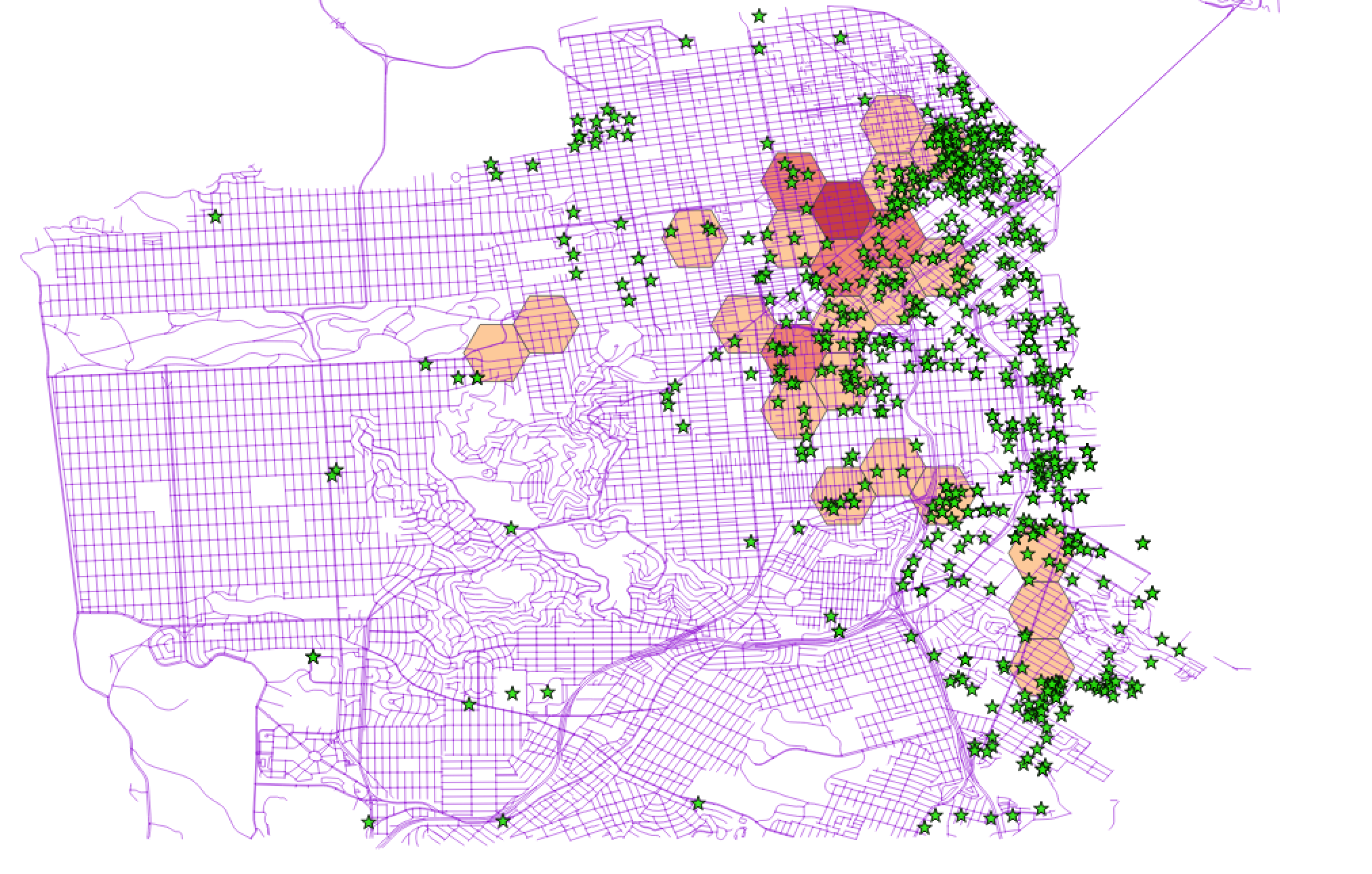
Here's what the finished map looks like (as a static image for now, we'll worry about interactivity later):
Where the data came from
I literally conceived the topic of my map by looking at the first page of data.sfgov.org's listing of popular datasets:
- Mobile Food Facility Permits - not all of these of latitude/longitude data, but most of them do.
- SFPD crime incidents - Looking for incident reports of criminal drug activity is obviously not the most accurate lens to gauge all drug activity. But good enough fo rnow. I used the data.sf.gov website's filtering option – to filter for the past few months of data – before exporting the data to CSV. However, I did not filter by category (i.e. for crimes categorized as being drug crimes). I can do this in QGIS, and it's easier to adjust filters from within QGIS.
- Streets of San Francisco (centerlines) - why street data? Because it's more interesting than the usual boundary data you see for cities. At the very least, seeing the streets makes it more obvious which food carts are the most accessible by vehicle.
How I made the map with QGIS
I'm assuming you've gone through Mike Corey's QGIS tutorial a couple of times (and tried tweaking/breaking it) so I won't explain the basic steps. My workflow was quite a bit simpler than Corey's, mostly because I avoid the topic of map projections altogether…though I'm not sure I was justified in doing so with the street line data…
Importing the point data
Both the mobile food permit and crime incident datasets have latitude and longitude columns (in the crime dataset, the columns are X and Y). After downloading them, I imported them as Delimited Text Layers. Unlike the example data in Corey's tutorial, both of my CSVs have a Geometry definition with Point Coordinates (i.e. latitude and longitude columns).
After importing both layers, my project space looked like this; the yellow dots are all reported crime incidents in the past few months, and the green dots are the locations for the mobile vendor food permits:

At this point, we can hide the food-truck layer just to make things easier to see. Remember that these yellow dots are all crimes. If I want to show just drug-related crimes, I need to filter based on the SFPD's Category column (skim the data page to see the various columns and values) and remove all non-drug-related incidents.
As shown in Corey's tutorial, to filter a layer, right-click the layer and select the Filter command. And then just type in the conditions on which to filter, i.e. not much different than a SQL WHERE clause:
This is how I've described my filter condition:
"Category"='DRUG/NARCOTIC'

And this is the result:

There's far fewer crime-dots, but enough to make the map too cluttered when we add the food-truck-layer. So the next strategy is to bin the crime dots, i.e. create a kind of heat map that shows areas with a high density of crime incidents, so that there's no need to show the individual incidents as dots.
Making my own boundaries and grid
While there is San Francisco neighborhood boundary data, my editorial judgment is that physical distance – not arbitrary man-made boundaries – is the more compelling way to geographically cluster crime incidents.
Corey covers this in the Create hexagonal bins section of his tutorial. I like hexagons too, but you can use diamonds, rectangles, etc. The first step is just to create a layer of hexagons. Warning: the most time-consuming part of this map-making process, for me, was just deleting/recreating the grid until I got it to have the right-sized hexagons…
Here's what that layer looks like: a bunch of hexagons.

Adding a data-filtered hexagon layer
In Corey's tutorial – under the section Count the earthquakes in each bin – review how he uses the Vector > Analysis > Points in polygon… command to combine his hexagon-grid-layer with the ok_quakes_only as the input point vector layer. For my scenario, the input point vector layer is whatever I named my drug-crime-incident-point layer.
I tell QGIS to count the number of drug-crime-dots per hexagon and save that as a field/column named pointcount
After doing that, I follow the instructions in the section titled Color bins by count. I used the Style panel to be dependent on a Graduated basis (i.e. lighter/darker colors based on pointcount value). I tweaked the settings to my liking but not out of any scientific/mathematical principle. It just looks nice to me:

All together
Here's all the layers shown together – the hexagons-colored-by-drug-crime-density, the drug-crime-incidents as dots, and the mobile food vendor locations, which I've changed to be green stars for fun.
And then I've added the street map shape data beneath it all. Why purple? Because that's what QGIS randomly selected and I liked it:

Declutter
Not bad. But remember our main objective is not just to throw a bunch of data together, but make a meaningful visualization from it. Or, at least make it easy to interpret by showing only the important parts. I already did that by filtering out all non-drug crimes (someone else who wants to try my idea might look at another kind of crime). But those yellow dots are kind of redundant, aren't they? After all, we went through the trouble of creating the hexbin-density-layer to simplify the crime dot layer. What's the point in showing the crime dots individually?
Below is the final version of my map, but all I've done is remove a few layers (including the boring, not-terribly-dense hexagons). The screenshot includes my layers subpanel so you can see what I've left out:
